Git Revision Selection and Expressions A…B#
While using git it’s common to use object identifiers to operate on the underlying objects: checking branches out, reverting a commit, resetting to a given point in the history, and more.
We do this without even thinking, referring to branches by their string identifier or commits by their full or partial hash. However, in git there are alternative ways to refer to commits by doing so relative to other identifiers.
This brief tutorial is aimed at understanding alternative revision selection mechanisms [1]. Do not try to remember this all, read through it and keep a faint recollection that it’s possible and what it looks like so you can, if needed, come back to it in the future.
If the term “object identifier” confuses you, in the Git tutorial I briefly explain how every git object has a corresponding object identifier and what they look like. In the case of commits it’s a hash, in the case of branches it’s a name in the form of a string, but, as we’ll see here, there’s more to references or so-called revision selections than meets the eye.
Now, being familiar with the term object identifier you might ask yourself, “what on earth is a revision?”. There’s not much to it, really, according to the official documentation a revision is usually a commit but can also be other alternative ways of referring to a commit or a group thereof [2]
Addendum#
Once you’re done reading this article, you can continue by having a look at the related content I’ve linked below.
By Commit Hash#
Of course you already know that one of the most natural ways to interact with your git repository is by using commit hashes to refer to and access different snapshots as shown below.
$ git show 169f46f7ed9d3fd4a5978974d70c46d20455dd07
commit 169f46f7ed9d3fd4a5978974d70c46d20455dd07 (HEAD -> master, origin/master)
Author: Jayson Salazar Rodriguez <noreply@jdsalaro.com>
Date: Fri Jul 7 02:56:56 2023 +0200
[...]
This type of revisions is used extensively in the git tutorial, however, it’s also possible to use partial hashes as long as they are at least 4 characters long and unambiguous.
$ git show 169f46f7ed9d3fd4
[...]
The above, for example, is perfectly valid, as is the following:
$ git show 169f46f
[...]
By Branch name#
Revisions can be also be branch names, in which case you’re implicitly referring to the head of said branches.
$ git show master
commit 169f46f7ed9d3fd4a5978974d70c46d20455dd07 (HEAD -> master, origin/master)
Author: Jayson Salazar Rodriguez <noreply@jdsalaro.com>
Date: Fri Jul 7 02:56:56 2023 +0200
[...]
Naturally, and as explained in the tutorial, checked out we refer to said branch as the HEAD(note the use of capitalization) instead:
$ git show HEAD
commit 169f46f7ed9d3fd4a5978974d70c46d20455dd07 (HEAD -> master, origin/master)
Author: Jayson Salazar Rodriguez <noreply@jdsalaro.com>
Date: Fri Jul 7 02:56:56 2023 +0200
[...]
By Ancestry#
Git offers two ways in which one can refer to revisions by ancestry: using ^ and ~; of which the later is the most widely used.
^n refers to the nth parent of a revision. It’s useful to directly reference a given parent of a particular merge commit or revision.
Most of the time, however, we are not working with merge commits but with simple commits which only have one parent. That’s why ~ is popular, it’s a shortcut for ^1, that is the first parent of the commit in question. Consider the figure below, it should clarify this ordeal once and for all.
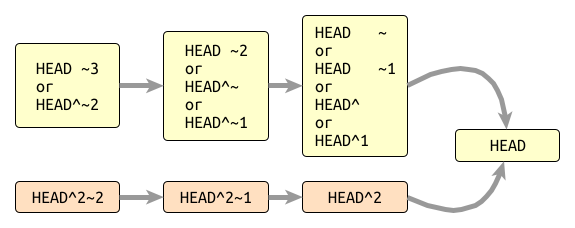
Git Revision Selection#
I am personally not suggest referring to git revisions with ancestry expressions; it’s way too easy to make mistakes using HEAD~1 when what you actually meant was HEAD~2 or even HEAD^2~2. Therefore, I think it’s less error prone to use git log, or in my case glog as per Wrist-friendly Git Shortcuts and Aliases #️⃣, for finding the commit or commits you’re interested in and using their identifier for further operations.
For the sake of completeness, and because it’s understanding what we’re after, here’s another example to help you internalize the meaning of ^ and ~.
$ git show HEAD~2
commit bf4c70e491e9d7b00cdeec8ff4872f20602cb6ca
[...]
$
$ git show HEAD^~
commit bf4c70e491e9d7b00cdeec8ff4872f20602cb6ca
[...]
$
$ git show HEAD^1~1
commit bf4c70e491e9d7b00cdeec8ff4872f20602cb6ca
[...]
By Range#
Now, if revision selection by ancestry was my least favorite approach, this is my one of my favorite git gimmicks: being able to find commits between revisions.
To achieve this git offers the dot-dot syntax, with which by using A..B we can refer to the commits between the revisions A and B. Keep in mind that A..B refers to commits reachable from B but not from A. A more natural way to understand that is by thinking that A..B is equivalent to what has happened since A from the perspective of B, or changes that are in revision B but not in A.
An example is worth a thousand words, so have a look at the following:
$ git branch -a
experiment
* main
$ ls
main.txt
$ cat main.txt
HELLO
So far we have a main branch with main.txt in it.
$ git checkout experiment
Switched to branch 'experiment'
$ ls
experiment.txt final.txt main.txt
$ cat *
WORLD
!
HELLO
The experiment branch, as shown above, is based off main and contains experiment.txt and final.txt in addition to main.txt.
If we ask git what has happened so far in the experiment branch we get the following:
$ git log experiment
commit 476e3b42466ea225c2d917ab4d865702a0cdff3e (HEAD -> experiment)
Author: Jayson Salazar Rodriguez <noreply@jdsalaro.com>
Date: Mon Jul 10 13:02:55 2023 +0200
On branch experiment
Changes to be committed:
new file: final.txt
commit bf4c70e491e9d7b00cdeec8ff4872f20602cb6ca
Author: Jayson Salazar Rodriguez <noreply@jdsalaro.com>
Date: Mon Jul 10 13:02:22 2023 +0200
On branch experiment
Changes to be committed:
new file: experiment.txt
commit 1899afec1ed8aff540903bc3646774409303b5ba (main)
Author: Jayson Salazar Rodriguez <noreply@jdsalaro.com>
Date: Mon Jul 10 13:01:37 2023 +0200
On branch main
Initial commit
Changes to be committed:
new file: main.txt
If we, however, are interested only in what has happened in experiment since it was based of main, we can use main..experiment and receive a much more useful output:
$ git log main..experiment
commit 476e3b42466ea225c2d917ab4d865702a0cdff3e (HEAD -> experiment)
Author: Jayson Salazar Rodriguez <noreply@jdsalaro.com>
Date: Mon Jul 10 13:02:55 2023 +0200
On branch experiment
Changes to be committed:
new file: final.txt
commit bf4c70e491e9d7b00cdeec8ff4872f20602cb6ca
Author: Jayson Salazar Rodriguez <noreply@jdsalaro.com>
Date: Mon Jul 10 13:02:22 2023 +0200
On branch experiment
Changes to be committed:
new file: experiment.txt
By Logical Negation#
Finally, it’s also possible to select revisions that are not reachable from a given revision:
$ git log ^main ^experiment
$
Of course we receive no output, we only have two branches and there are no commits which are not reachable from either main or experiment.
Using the commit hashes of both heads yields, as expected, the same result:
$ git log ^1d9156823ae162746e8e8c974e201b57fefc097b ^1d9156823ae162746e8e8c974e201b57fefc097b
$
Final Words#
That was brief, but I hope still interesting. You will probably seldom need all details presented here, but my idea is for you to know there’s a method to the madness and know what to look for whenever you come across a somewhat cryptic looking revision reference or even perhaps need to start using them.
Stay in touch by entering your email below and receive updates whenever I post something new:
As always, thank you for reading and remember that feedback is welcome and appreciated; you may contact me via email or social media. Let me know if there's anything else you'd like to know, something you'd like to have corrected, translated, added or clarified further.