Git for Beginners: Zero to Hero 🐙#
Git plays a crucial role in the software development industry and should therefore be part of every developer’s toolkit. Both experienced and beginner developers can increase their productivity by leveraging a code versioning system as powerful as git. Unfortunately, introductory materials are often either too shallow, making readers feel like they only scratched the surface, or too long-winded, diving into details which needn’t interest everybody.
Seeing as colleagues and students often ask me about good, self-contained guides, I decided to republish this guide for git beginners as well as those looking for a refresher.
Addendum#
Once you’re done reading this tutorial, you can continue your git journey by having a look at the related content I’ve linked below.
Discussion#
This article was heaviliy discussed on Reddit, Lemmy at programming.dev/c/learn_programming and programming.dev/c/git as well as Tildes.
Feel free to let me know in case you think I ought to include any other conversations related to this publication.
Introduction#
This is partly a tutorial, if read sequentially, and partly a reference, for those already familiar with git. The first part is a short introduction to git basics. The second section presents a glossary of sorts where the terms and processes I consider most important are explained as well as relevant examples given. It starts by defining what git repositories and commits are but progresses quickly into more interesting topics such as the differences between an arbitrary head and the HEAD, dirty working trees among others.
Warning
This tutorial is a bit long but that is a necessary evil. As mentioned before, I’ve tried to make it neither too shallow nor too deep. I hope you enjoy it and don’t hesitate to share your feedback with me via social media or email.
Note
Here we won’t deal, on purpose, with GitLab nor GitHub, since they are certainly powerful platforms but can be confusing for git newbies. At some point I’ll eventually get to finishing my drafts on those two and post them; stay tuned via social media or the mailing list 👍
Note
You’ll get the most out of this tutorial if you actually follow along. Whenever you see a terminal output window, go ahead and open up one yourself and try out the commands shown and compare your results with the output shown.
The Intuitive File Workflow#
While programming we continuously perform four basic actions which result in changes to the code-base: creating, modifying, checking the status of, and deleting files. This is obvious to everyone, even if intuitively, who writes computer programs. This workflow will be our reference point through the article. Here’s where we would like to have a version control system which helps keeping track of the code-base and the operations performed on the objects that comprise it and ideally enhances and not hinders our individual or group workflows and dynamics.
Git#
Git is a distributed version control system that emphasizes speed, data integrity and support for non-linear workflows. It was created by Linus Torvalds in 2005 as an aid for the development of the Linux kernel, with other kernel developers contributing to its initial version[1].
Git aims at providing answers for the following questions and many more to anyone with access to a so-called git repository:
What files exist currently in the code-base?
Of those files, which ones comprise the latest version of the code-base?
Which files have been modified but not saved?
Which have been saved but not shared with the team?
What are the changes that led to a particular file looking the way it does?
What alternative versions of the files are there?
Who has edited a given file and when?
Having said this, you now might be asking yourself how to actually leverage git and what a sensible workflow looks like that helps you manage your programming projects better; read on.
The Git Workflow#
With git there’s no one single valid workflow. There are ways of working with git which resemble version control systems such as Subversion and there are more git-typical workflows which fully leverage its distributed and dynamic capabilities. Workflows, that is the way programmers work on projects simple and complex, were a fundamental consideration when Linus created Git to help manage the development process of the Linux kernel:
while there were some other SCM’s that kind of tried to get the whole distributed thing, none of them did it remotely well. I had performance requirements that were not even remotely satisfied by what was available, and I also worried about integrity of the code and the whole workflow, so I ended up just deciding to write my own
My aim here is not to thoroughly compare different git workflows, a good overview of some common ways teams leverage git can be found in the footnotes[2][3], but to have a look at one which hopefully fits every beginner and intermediate git user.
Having said that, for local repositories there is pretty much only one way to use git. The difference between local and remote repositories is explained later. For the time being we focus on the local git workflow, which consists of four steps. These steps can be mapped, to some extent, to those constituting the “intuitive workflow” described previously:
Create files or perform changes.
Collect one or more of the changes performed in a unit called a commit.
Save that set of changes to the history of a given development line.
Make new versions or snapshots of the codebase available to others.
Before any of those can happen, a git repository needs to be set up properly first by:
Initializing the repository.
Configuring the repository.
Creating the initial line of development in the repository.
That is also the usual life-cycle of any given file while working with git locally. Steps one to three are usually only performed once. So, they shouldn’t be understood per se as part of the workflow.
The following image illustrates the life-cycle of a file in the git world more clearly:
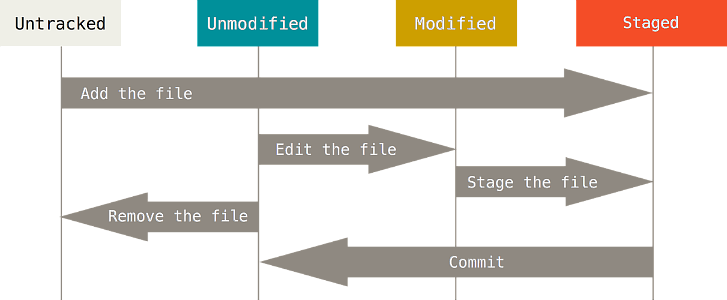
Lifecycle of files in git#
Once a file has been created or moved into a git repository, a directory managed by git, it starts as untracked. That means the repository hasn’t been told to monitor the changes done to that file.
One can tell git to start monitoring a file by using the command git add mynewfile. At this point git knows that the file mynewfile should be tracked. What actually happened, however, is a bit more complex. By issuing git add mynewfile one actually tells git to put the current version of mynewfile in a list of changes made to the code-base. If we added another file called myotherfile, the current version of that file will also be added to that list of changes.
After the user has grouped several changes in the aforementioned list of changes, called the stage or index, they can decide to save them into the current version of the code-base.
In other words, by staging a file of which git has no knowledge we tell git to put the change addition of a new file to the working directory in the index. In this way we group that change with our other changes.
A change or group of changes which have been put in the index, that is grouped together and prepared for storage, is called a prepared commit and can then be saved to the history of the code-base. The act of saving one such prepared group of changes is called committing and it results in the creation of a commit (also commonly called snapshot or revision) in the project’s history.
Files whose current state has been saved in the project’s history are deemed unmodified and require no further action from the user. As shown by the diagram above, they can still be removed or edited if desired. If removed from the repository, they become untracked and we are back at square one. If edited, the files are now considered modified. A file being in modified state means that their current working copy differs from the version git has of it in the history of the repository. If the user so desires, the changes can once again be staged and committed.
This is the basic idea of working locally with git. We tell git to track files, perform changes and tell it at which point in time to take snapshots of the code-base by saving the changes made.
In order to keep an overview of what is being discussed, the following image might come in handy. We observe that commit objects, formerly described as sets of changes, are connected with each other, this is the repository’s history. Furthermore, the working directory or working tree consists of those files which can be seen by the user in the directory. The stage or index keeps the changes which will later be saved as a single commit in the project’s history later on. Finally, lines of development which look like sub-chains made out of commits are also shown and these are called branches, they are alternative versions of repository.

These are some git objects which are dealt with quite often while in the git world#
https://marklodato.github.io/visual-git-guide
That was a superficial, albeit much needed, overview of git, we now move onto more interesting territory.
Glossary#
User#
A user is an entity, human or otherwise, which performs actions on the code-base or other artifacts related to or being tracked by git.
Working Tree#
The contents of the directory where a git repository has been initialized, i.e. ~/gitrepo or C:\Users\jdsalaro\gitrepo.
Repository#
A git repository is any directory which has been initialized to be one. It can be said that every git repository starts as an empty one only composed of its configuration. As time progresses, it becomes a compilation of all the branches as well as commits, loosely speaking lines of development and repository snapshots respectively, that have led to the code-base becoming what it is.
Object Identifier#
As already mentioned, a git repository is an abstract term describing the grouping of all branches, commits and more comprising a code-base or project. In order to track such objects, git relies on calling them a name, these are the hashes in the case of commits but are generally referred to as object identifiers. Every object tracked by git has an object identifier.
A branch name can be main or feature42 and commits are identified by hashes or string literals, i.e. 9d8e3d229cc6bb57b156848b1fb4df6bc5fda1c1 and this-is-a-special-commit.
Configuration#
Git is quite powerful and can be greatly customized. To make this possible it relies on numerous configuration files. The local configuration for a given git repository lives in the .git sub-directory. This, however, is not the only place where information related to git’s configuration and the repository is stored.
Git looks for its configuration in the following places:
/etc/gitconfig~/.gitconfig.git/config
Additionally, files such as .gitignore and .gitmodules exist for particular purposes. The former defines which files git should never track nor be seen by it as part of the code-base although they exist in the working tree. The latter deals with git sub-modules, a way to reference and manage git repositories within git repositories.
Upon initialization, your git repository will look as follows:
1[~/gitrepo]$ git init .
2Initialized empty Git repository in ~/gitrepo/.git/
3
4[~/gitrepo]$ ls -a
5drwxrwxr-x 7 user user .git
⚠️ Go ahead, open up your operating system terminal and initialize a local git repository using the commands listed above. We will need that repository for you to follow along. In case you need help installing git on your operating system, there are clear and easy to follow instructions on how to do so in the official git book.
The files used by git for storing its configuration can be modified manually, but it is more comfortable to use the tool itself to perform some common operations such as modifying the email and username used by git for new commits.
1[~/gitrepo]$ git config --system user.name
2
3[~/gitrepo]$ git config --global user.name jdsalaro
4
5[~/gitrepo]$ git config --global user.name
6jdsalaro
7
8[~/gitrepo]$ git config --local user.name
9
10[~/gitrepo]$ git config --global user.email "noreply@jdsalaro.com"
11
12[~/gitrepo]$ git config --global user.email
13noreply@jdsalaro.com
14
15[~/gitrepo]$ git config color.ui true
We just issued the git config command for several scopes. The system scope is the one associated with /etc/gitconfig. --global refers to the one present in the user’s home directory, ~/.gitconfig. Finally, --local refers to the configuration file in ~/gitrepo/.git/config.
Git is a really well documented software. For a more detailed listing of configuration options one can use git config -h. The -h option works similarly for other commands and should be kept present.
Index#
The index, also called the staging area or cache, is the place where new changes the user is preparing and wants git to know about are kept in order to be committed later on. As such, when the user creates a file in their working tree it isn’t necessarily known to git as a file whose state it should track and recorded in the repository’s history, also called commit tree. To do this, the user must add the change to the index.
In the following example we can see, that although the working directory contains two files, the index, shown using git ls-files -s only contains one. That is, the user has told git to keep track of myfile but not of README.md.
Worded differently, the change creation of myfile was added to the stage but creation of README.md was not.
1[~/gitrepo]$ ls -a
2drwxrwxr-x 7 user user .git
3-rw-rw-r-- 1 user user myfile
4-rw-rw-r-- 1 user user README.md
5
6[~/gitrepo]$ git ls-files -s
7100644 d082433a347e0a1518124642561f537b122bda71 0200 myfile
Go ahead and create the two files listed and add myfile to the index via git add myfile.
Commits#
A commit can be understood as a group of changes which have been ‘saved’ or committed to the local repository by telling git to do so. They are also referred as snapshots since each commit captures the state of the project at the time it has been added to the history. A commit ‘contains’ among others information about the identity of the user who committed the set of changes, an object identifier for the commit, the date on which the changes were committed and the new version, also called snapshot, of the files which were modified.
A commit looks like this:
1[~/gitrepo]$ git show 19d8e3d229cc6bb57b156848b1fb4df6bc5fda1b
2
3commit 19d8e3d229cc6bb57b156848b1fb4df6bc5fda1b
4Author: user <noreply@jdsalaro.com>
5Date: Fri May 20 21:15:48 2016 +0200
6
7 initial commit
8
9 diff --git git.md-data/.gitmodules b/.gitmodules
10 new file mode 100644
11 index git-tutorial000..45dfaa2
12 --- /dev/null
13 +++ b/.gitmodules
14 @@ -0,0 +1,9 @@
15 +[submodule "plugins"]
16 + path = plugins
17 + url = https://github.com/getpelican/pelican-plugins
18 +[submodule "themes"]
19 + path = themes
20 + url = https://github.com/getpelican/pelican-themes
Feel free to ignore most of the details in the output of the command, we will deal with commits and their structure in more depth later on.
Branches#
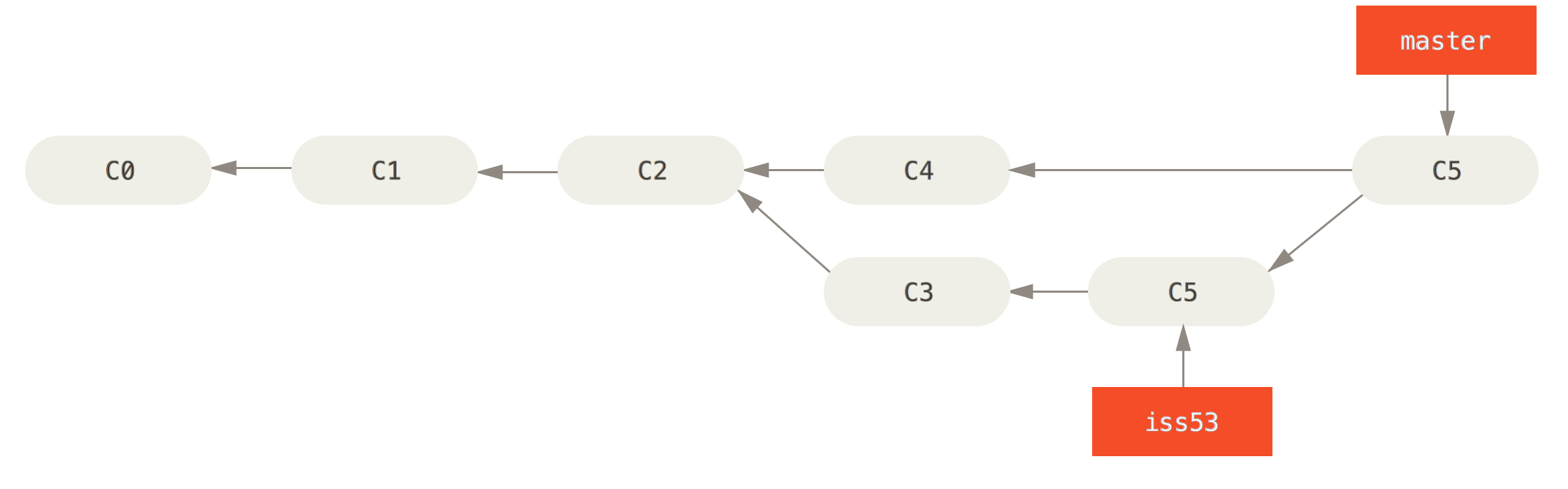
Two git branches with branch iss53 being merged onto the main branch#
A branch is an independent development track on a given repository. Every branch has its own working tree, staging area and project history. They exist inside the repository itself and are usually based on a commit from another branch in the repository. Every repository has a ‘main’ branch upon its creation. New developers coming to a project usually base their work on the main branch, then new branches are created where modifications are introduced and then these branches are merged onto the main branch.
1[~/gitrepo]$ git branch -a
2* main
3 new
4 remotes/origin/main
In the output shown above, the repository in the ~/gitrepo directory and its three branches can be seen; in other words the three development lines of the project. The first one and the one being used or checked out, as pointed out by the asterisk, is the main branch. The second one is another local branch called new. The third is a so-called remote branch described by remotes/origin/main. Remote branches will be discussed later on.
Heads and the HEAD#
In git a head is a pointer to the tip of a branch or a revision, more to come on this topic later. The takeaway at this point is, however, that there is a special head, the HEAD, which simply gives a name to the commit on which the current working tree is based. The HEAD can be understood as a pointer to the most recent committed version of the code-base in the branch currently in use.
In the following example it can be observed that the git history of the current main branch contains only three commits. The latest commit being the one with hash 518defa8757902f3be2b17cca0dbfe48fae87465. One can see from the output of the show command that the HEAD points at the last commit made in the main branch.
1[~/gitrepo]$ git log --pretty=oneline --max-count=4
2
3518defa8757902f3be2b17cca0dbfe48fae87465 fix README.md
4f37e6f56a322cd22f9e367f4e1f76d7c9b8b4575 add README.md
519d8e3d229cc6bb57b156848b1fb4df6bc5fda1b initial commit
6
7[~/gitrepo]$ git show HEAD
8
9commit 518defa8757902f3be2b17cca0dbfe48fae87465
10Author: jdsalaro <noreply@jdsalaro.com>
11Date: Fri May 20 21:35:35 2016 +0200
12
13 ...
The working directory, that is the files, the user can see are based on this commit pointed at by the HEAD. Modifications committed by the user at this point will be put on top of the commit to which the HEAD points. The newly created commit would then have the old HEAD as child in the projects history.
Remotes#
A remote can be understood as an identifier given to a repository which exists on some system, is available to you and can be reached via a path such as https://domain.com/repo.git or ssh://user@server.com:/opt/git/repo.git.
One such example would be as follows:
1$ git remote -v
2origin https://github.com/getpelican/pelican-themes (fetch)
3origin https://github.com/getpelican/pelican-themes (push)
In this example, origin is the identifier given to the repository at https://github.com/getpelican/pelican-themes.
As with any repository, remote repositories have branches, commits and histories of their own. However, they would be of little use if one was not be able to track their contents and potentially alter them. Git solves this problem by keeping track of the contents in remote repositories using so-called local tracking-branches. These branches work as local caches which reflect the status of a remote up until the point it was last fetched.
As can be seen below, git is tracking the contents of the origin remote at https://github.com/getpelican/pelican-themes by using local copies of its branches, namely main and previews.
1git branch -a
2* main
3 remotes/origin/HEAD -> origin/main
4 remotes/origin/main
5 remotes/origin/previews
Origin and Origin main#
Two keywords anyone interested in git is bound to find sooner or later are main, origin and the combination of both origin main. They are, once again, nothing but default names given to certain git objects. main, also commonly master, is the name given to the default development branch of any repository. As mentioned before, once a repository is initialized using git init a main branch is created. origin is the default name given to the remote repository to which local changes will eventually be pushed. origin main, quite coherently, refers to the main branch at the remote repository origin. Note that neither main nor origin are a must. One can indeed give an arbitrary name to the default branch of a repository and the same applies for naming remotes.
Git Operations#
Checking Out#
Checking out refers to the act of updating the HEAD to a point determined by the head of a branch or an arbitrary commit in an other branch. As exemplified below, checking out a branch leads to the modification of the HEAD. Naturally, this leads to the current working tree, index and history being swapped by those in the branch which is being checked out.
1[~/gitrepo]$ git branch -v
2* main 5bc416d seventh
3 new 8ffdf6e sixth
Here we see that two branches are present. The head or latest commit of the main branch is pointing to the commit with message seventh. The head of the new branch is pointing to a commit with message sixth. Finally, note that the HEAD is also pointing to seventh.
1[~/gitrepo]$ git show HEAD
2commit 5bc416dcd1f353375f846fb655ba68c05044fd18
3Author: jdsalaro <noreply@jdsalaro.com>
4Date: Mon May 23 09:43:26 2016 +0200
5
6 seventh
7
8diff --git git.md-data/seventh b/seventh
9new file mode 100644
10index git-tutorial000..e69de29
However, if we check out the branch new, the HEAD will now point to sixth.
1[~/gitrepo]$ git checkout new
2Switched to branch 'new'
3
4[~/gitrepo]$ git show HEAD
5commit 8ffdf6e97a1c9b752062bea51d5db993b74cb56a
6Author: jdsalaro <noreply@jdsalaro.com>
7Date: Mon May 23 09:41:58 2016 +0200
8
9 sixth
10
11diff --git git.md-data/sixth b/sixth
12new file mode 100644
13index git-tutorial000..e69de29
As a general remark, there is a special case when the HEAD points to a commit which is not the head of a local branch. This is called a detached state, it’s a somewhat intricate topic which isn’t in the scope of this article.
Two things suffice at this point. First, checking out anything other than the head of a local branch leads to a detached state. Second, this can be easily solved by checking out a head of a local or a tracking branch.
The detached HEAD state is meant to allow for experimenting with changes based on a commit at an arbitrary point in the branch history [4].
Merging#
You have most likely asked yourself what happens when several branches exist on a git repository. What if a developer wishes to incorporate changes found in branch X into the main branch of the project?
This is where merging comes into play. Merging refers to the act of taking changes found on another branch and applying them to another. Since git is a branch-based version control system, code-bases managed with it are usually composed of several, commonly short-lived, branches, all of which evolve in parallel. For example, if three developers were to work on a software project with a plugin-based architecture, they could have three branches called plugin A, plugin B and plugin C. They could then at a later point in time merge their respective finished features to the main branch. In this way plugin A, plugin B and plugin C would become part of main and each developer could start working on some other features, i.e. feature A, feature B and feature C.
Here is a quick example showing git merging in action. First a git repository is initialized and the contents of the working tree listed.
1[~/gitrepo]$ git init .
2Initialized empty Git repository in ~/gitrepo/.git/
3
4[~/gitrepo]$ ls -a
5total 12
6drwxrwxr-x 3 user user 4096 Jun 6 21:21 .
7drwxrwxrwt 19 user user 4096 Jun 6 21:21 ..
8drwxrwxr-x 7 user user 4096 Jun 6 21:21 .git
We then create two files, add them to the index and create a commit with message first, second.
1[~/gitrepo]$ touch first
2
3[~/gitrepo]$ touch second
4
5[~/gitrepo]$ git add .
The index now contains the files first and second. Now we commit them with a commit message which explains what was done.
1[~/gitrepo]$ git commit -m "first, second"
2[main (user-commit) 8e1fba3] first, second
32 files changed, 0 insertions(+), 0 deletions(-)
4create mode 100644 first
5create mode 100644 second
We now create a new branch called mybranch and verify that the contents of main have been included in this branch. That is, mybranch is based on the last commit done to main.
1[~/gitrepo]$ git checkout -b mybranch
2Switched to a new branch 'mybranch'
3
4[~/gitrepo]$ ls -a
5total 12
6drwxrwxr-x 3 user user 4096 Jun 6 21:22 .
7drwxrwxrwt 19 user user 4096 Jun 6 21:21 ..
8-rw-rw-r-- 1 user user 0 Jun 6 21:22 first
9drwxrwxr-x 8 user user 4096 Jun 6 21:24 .git
10-rw-rw-r-- 1 user user 0 Jun 6 21:22 second
Now we add a file called third to mybranch and commit the changes.
1[~/gitrepo]$ touch third
2[~/gitrepo]$ git add .
3
4[~/gitrepo]$ git commit -m "third"
5
6[mybranch 2e4db31] third
71 file changed, 0 insertions(+), 0 deletions(-)
8create mode 100644 third
We observe that third is now part of the repository.
1[~/gitrepo]$ ls -l
2total 12
3drwxrwxr-x 3 user user 4096 Jun 6 21:25 .
4drwxrwxrwt 19 user user 4096 Jun 6 21:21 ..
5-rw-rw-r-- 1 user user 0 Jun 6 21:22 first
6drwxrwxr-x 8 user user 4096 Jun 6 21:25 .git
7-rw-rw-r-- 1 user user 0 Jun 6 21:22 second
8-rw-rw-r-- 1 user user 0 Jun 6 21:25 third
Similarly, we switch to the main branch and create a file called fourth, add it to the index and commit it.
1[~/gitrepo]$ git checkout main
2Switched to branch 'main'
3
4[~/gitrepo]$ ls -a
5total 12
6drwxrwxr-x 3 user user 4096 Jun 6 21:25 .
7drwxrwxrwt 19 user user 4096 Jun 6 21:21 ..
8-rw-rw-r-- 1 user user 0 Jun 6 21:22 first
9drwxrwxr-x 8 user user 4096 Jun 6 21:25 .git
10-rw-rw-r-- 1 user user 0 Jun 6 21:22 second
11
12[~/gitrepo]$ touch fourth
13
14[~/gitrepo]$ git add .
15
16[~/gitrepo]$ git commit -m "fourth"
17[main 8f5e7a5] fourth
181 file changed, 0 insertions(+), 0 deletions(-)
19create mode 100644 fourth
20
21[~/gitrepo]$ git branch
22* main
23 mybranch
As expected, first, second and fourth are part of the main branch.
1[~/gitrepo]$ ls -a
2
3total 12
4drwxrwxr-x 3 user user 4096 Jun 6 21:25 .
5drwxrwxrwt 19 user user 4096 Jun 6 21:21 ..
6-rw-rw-r-- 1 user user 0 Jun 6 21:22 first
7-rw-rw-r-- 1 user user 0 Jun 6 21:25 fourth
8drwxrwxr-x 8 user user 4096 Jun 6 21:25 .git
9-rw-rw-r-- 1 user user 0 Jun 6 21:22 second
10
11[~/gitrepo]$ git status
12
13On branch main
14nothing to commit, working directory clean
We list the contents of mybranch while having main checked out and note that the list of files looks different. In the case of mybranch, first, second and third are contained in the branch but fourth isn’t.
1[~/gitrepo]$ git ls-tree -r mybranch --name-only
2first
3second
4third
Now we merge mybranch with main.
1[~/gitrepo]$ git merge mybranch
2Merge made by the 'recursive' strategy.
3third | 0
41 file changed, 0 insertions(+), 0 deletions(-)
5create mode 100644 third
6
7[~/gitrepo]$ ls -a
8total 12
9drwxrwxr-x 3 user user 4096 Jun 6 21:26 .
10drwxrwxrwt 19 user user 4096 Jun 6 21:21 ..
11-rw-rw-r-- 1 user user 0 Jun 6 21:22 first
12-rw-rw-r-- 1 user user 0 Jun 6 21:25 fourth
13drwxrwxr-x 8 user user 4096 Jun 6 21:26 .git
14-rw-rw-r-- 1 user user 0 Jun 6 21:22 second
15-rw-rw-r-- 1 user user 0 Jun 6 21:26 third
16
17[~/gitrepo]$ git status
18On branch main
19nothing to commit, working directory clean
As can be seen above, we have successfully merged mybranch and its contents with main. This leads to third being incorporated in the main branch.
A visualization of the branch topology at this point can be shown by using git log as follows:
1[~/gitrepo]$ git log --pretty=format:'%h %ad | %s%d [%an]' --graph --date=short
2* 5c058b5 2016-06-06 | Merge branch 'mybranch' (HEAD -> main) [jdsalaro]
3|\
4| * 2e4db31 2016-06-06 | third (mybranch) [jdsalaro]
5* | 8f5e7a5 2016-06-06 | fourth [jdsalaro]
6|/
7* 8e1fba3 2016-06-06 | first, second [jdsalaro]
8[~/gitrepo]$ ^C
9[~/gitrepo]$
Using a visualization tool is also a possibility. At the moment I prefer gitg.
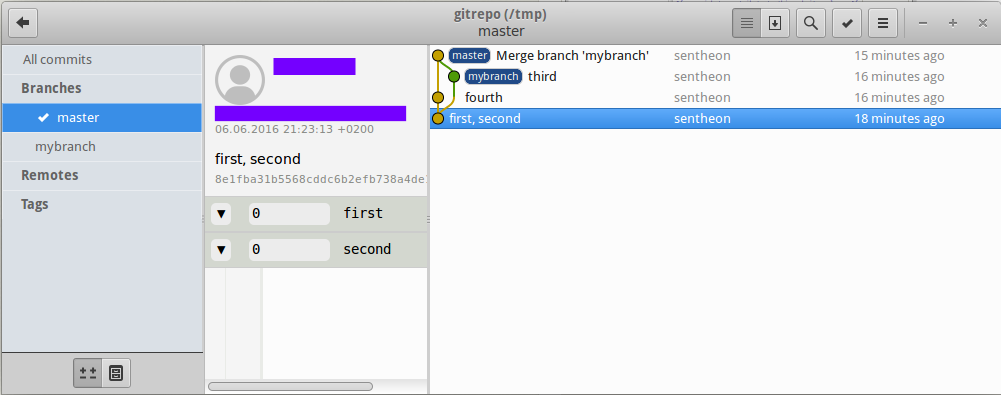
Visualizing branch structure with gitg#
The Idea of Tracking#
There are two senses in which the concept of tracking plays a role. One is the idea of git tracking changes made to a file. This is the case once the user tells git to stage the current status of a given file by using git add. Should a user have files in the local git repository which haven’t been staged(put in the index for later commit), then these are deemed untracked. As seen below, the README.md file is untracked, while the creation of .gitignore is shown as a staged change to be committed.
1[~/gitrepo]$ git status
2On branch main
3
4Initial commit
5
6Changes to be committed:
7 (use "git rm --cached <file>..." to unstage)
8
9 new file: .gitignore
10
11Untracked files:
12 (use "git add <file>..." to include in what will be committed)
13
14 README.md
Therefore, if we wanted the current status of README.md to be saved in our upcoming commit, we would have to add it to the index using git add README.md.
The other way in which the word tracking is used is in the context of branches. A local branch which also exists in a remote git repository can have a local branch which tracks the state of the remote one.
1[~/gitrepo]$ git branch -a
2* main
3 new
4 remotes/origin/main
In the image previously shown, remotes/origin/main is the tracking branch for the main branch in the associated remote repository. We will talk about remote repositories in a moment.
Dirty Working Trees#
A dirty file is one which git has been told to track and is different with respect to the index or with respect to the head of the branch. In other words, the dirty state of a repository’s working tree is defined by changes to files which are being tracked but haven’t been committed. Conversely, one can think of a clean working tree as a working tree where there are no changes to commit and there are no differences between the stage and the working directory.
Clobbering#
Clobbering refers to the action of overwriting a file. Knowing when your working tree finds itself in a dirty state is important, since switching branches, swapping thereby the current index and working tree, would lead to changes made to untracked files which don’t exist in the current branch but exist in the to-be-checked-out branch to be lost.
As an example, consider the following terminal output:
1[~/gitrepo]$ git ls-tree -r new
2100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 file
3
4[~/gitrepo]$ git ls-tree -r main
5
6[~/gitrepo]$ git branch -a
7 * main
8 new
9
10[~/gitrepo]$ ls -a
11total 12
12drwxrwxr-x 3 user user 4096 Mai 23 12:04 .
13drwxrwxrwt 18 user user 4096 Mai 23 12:04 ..
14drwxrwxr-x 8 user user 4096 Mai 23 12:04 .git
15
16[~/gitrepo]$ touch file
17
18[~/gitrepo]$ git checkout new
19error: The following untracked working tree files would be overwritten by checkout:
20 file
21Please move or remove them before you can switch branches.
22Aborting
We can see that there are two branches, new and main. main is currently tracking no files but the new branch contains file. Our HEAD is pointing to the head in main, as shown by the asterisk in the output of git branch -a. If we then create a file using touch file and don’t tell git to track it and save its state we are unable to checkout the new branch.
What git sees is that there are files in the working tree which are untracked in the current branch, main, and exist in the branch to be checked out, new. Since git doesn’t know what the state of the untracked file is, how is it supposed to know what the user wants to keep or to what extent? Checking out the new branch would lead to git clobbering file. Git will therefore not allow a checkout of new while the working tree is in a dirty state, since checking out new would lead to clobbering file in main.
Exploring The History#
The history is the collection of commits which have been made to a repository. It contains the histories of all branches which have ever existed in the repository, composed of course of the respective commits made to those branches. It need not be linear, as several branches can exist at any given time. This situation leads to a forked history, where at some commit a new branch comes into existence and is tracked independently of the initial main branch.
The following is a simple linear example for the history of a branch:
1$ git log --pretty=format:"%h - %an, %ar : %s"
2518defa - user, 2 days ago : fix README.md
3f37e6f5 - user, 2 days ago : add README.md
419d8e3d - user, 2 days ago : initial commit
This other one, however, shows two branches where the new branch is ahead of the main branch by one commit.
1[~/gitrepo]$ git log --graph --full-history --all --pretty=format:"%h%x09%d%x20%s"
2* 7527d23 (new) add third
3* e212506 (HEAD -> main) add second
4* 705b193 add first
In some sense, the previous example still presents a linear history, since the new branch is just one commit ahead of the main branch. Due to this, although they are two branches, their heads and commits which brought their heads to the current state are not different enough to think of them as two separate development lines.
The next example presents the history of a more non-linear and powerful workflow.
1[~/gitrepo]$ git ls-tree -r main
2100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 fifth
3100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 first
4100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 fourth
5100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 second
6100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 seventh
7100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 third
As can be seen, first the files being tracked by the main branch are listed using git ls-tree -r main. This shows a series of files starting with the first and ending with the seventh, excluding the sixth.
Afterwards, we list the files being tracked by another branch, the new branch. This time we only find the first, second and sixth files.
1[~/gitrepo]$ git ls-tree -r new
2100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 first
3100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 second
4100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 sixth
Now, one would like to know how it has come to be this way. Some kind of graphical representation would also be useful. For this we use git log --graph
1[~/gitrepo]$ git log --graph --full-history --all --pretty=format:"%h%x09%d%x20%s"
2
3* 5bc416d (HEAD -> main) add seventh
4* 04b25c8 add fourth and fifth
5| * 8ffdf6e (new) add sixth
6| * 5e4e01b remove third
7|/
8* 7527d23 add third
9* e212506 add second
10* 705b193 add first
From bottom to top, we see that in the beginning the first, second and third files where added to the main branch. Then a new branch was created, shown by the |/ bifurcation. In this new branch, the third file was removed and a sixth file was added. According to the history, the head of the new branch is still at the change where the sixth file was created and that change committed. Then, a commit was made to the main branch which created the fourth and fifth files. Finally, another file was created, the seventh, and this change committed. It is at this change, that the head of the main branch is pointing to.
Since, as the following terminal output shows, we have currently checked out the main branch, the HEAD of the repository is pointing to the head of the main branch, which was shown by git log previously as 5bc416d (HEAD -> main) add seventh.
1[~/gitrepo]$ git branch -v
2* main 5bc416d seventh
3 new 8ffdf6e sixth
Diffing#
Diffing refers to the action of comparing two objects, in this case two git objects. By using git diff one can compare a file in the HEAD with its version in a remote branch. One can also compare two commits with each other and similarly two files with each other. There are many possibilities for what can be achieved with git diff. It is sufficient to say that diffing is a central process and that the result of diffing two objects is an annotated output which shows what has been changed, i.e. added or deleted.
Taking an arbitrary repository as an example, a diff between the HEAD and the fourth latest commit may look similar to this:
1[~/gitrepo]$ git diff HEAD~4 HEAD
2diff --git git.md-data/myfile b/myfile
3index b793f86..555b214 100644
4--- git.md-data/myfile
5+++ b/myfile
6@@ -1,3 +1,2 @@
7Hello world
8-Goodbye world
9Hello again
10\ No newline at end of file
We see that the only difference is the absence of the line Goodbye world.
Although this output is enough for simple modifications, following changes by means of pluses and minuses gets tedious quite fast. Fortunately, there are several graphical tools which can be used to visualize the result of a diff. Diffuse is one such tool and is, as of today, my favorite one.
Diffuse can be set as default diff.tool by modifying the configuration variable diff.tool
1[~/gitrepo]$ git config --global diff.tool diffuse
2[~/gitrepo]$ git difftool HEAD~4 HEAD
3
4Viewing (1/1): 'myfile'
5Launch 'diffuse' [Y/n]:
6[~/gitrepo]$
The result in diffuse is the following:
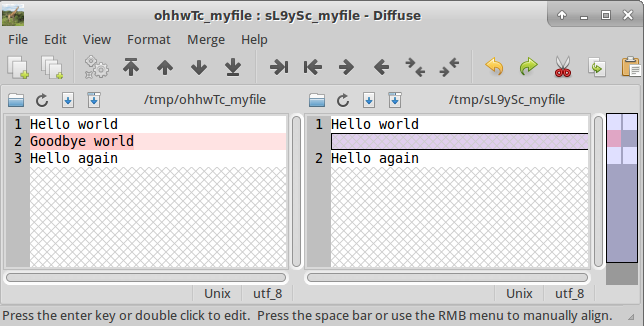
Performing diffs with diffuse as difftool#
Here we see the result of git diff in a more appealing and understandable representation.
Cloning#
Cloning refers to the act of copying a remote git repository to the user’s local file-system. One can clone a given repository by issuing git clone followed by the ssh, http or https URL as follows:
1[~/gitrepo/]$ git clone git@server.com:example.git .
2Cloning into '.'...
3remote: Counting objects: 24, done.
4remote: Compressing objects: 100% (17/17), done.
5remote: Total 24 (delta 2), reused 0 (delta 0)
6Receiving objects: 100% (24/24), done.
7Resolving deltas: 100% (2/2), done.
8Checking connectivity... done.
9
10[~/gitrepo/]$ ls -a
11total 20
12drwxrwxr-x 3 user user 4096 Jun 6 18:15 .
13drwxrwxrwt 17 user user 4096 Jun 6 18:15 ..
14drwxrwxr-x 8 user user 4096 Jun 6 18:15 .git
15-rw-rw-r-- 1 user user 11 Jun 6 18:15 myfile
After the cloning process the user now has a working copy of the remote git repository in his file system and can proceed to make changes accordingly.
Pushing#
Pushing refers to the act of transferring changes in a git repository which have happened locally to its remote. When a remote repository is involved, a new step has to be added to the three step git workflow. It becomes:
Make changes
Prepare a commit by staging said changes
Record the commit in the commit chain
Push commit to remote
In the following example a remote git repository is cloned. After cloning it the second file is created, added and committed.
1[~/gitrepo]$ git clone git@jdsalaro.com:example.git .
2
3Cloning into '.'...
4remote: Counting objects: 7, done.
5remote: Compressing objects: 100% (4/4), done.
6remote: Total 7 (delta 1), reused 0 (delta 0)
7Receiving objects: 100% (7/7), done.
8Resolving deltas: 100% (1/1), done.
9Checking connectivity... done.
10
11[~/gitrepo]$ echo 'Hello world' > second
12
13[~/gitrepo]$ git add .
14
15[~/gitrepo]$ git commit -m "second"
16[main 27a6184] second
171 file changed, 1 insertion(+)
18create mode 100644 second
We now look at the local history and see that the commit of second has been added to the history. Additionally, we observe that several commits were made before our own in the past. First README.md was added, then first, afterwards first was deleted and finally we added second.
1[~/gitrepo]$ git log
2commit 27a6184451cd4f383c9b28336a223bc791813384
3Author: jdsalaro <noreply@jdsalaro.com>
4Date: Mon Jun 6 00:20:56 2016 +0200
5
6 second
7
8commit 9d357c22216ae40cc8babb84b72d11fce03879dc
9Author: jdsalaro <noreply@jdsalaro.com>
10Date: Mon Jun 6 00:18:46 2016 +0200
11
12 remove first
13
14commit e14f7b699680fe4e8093e2b9a6764a2c1ef53ca0
15Author: jdsalaro <noreply@jdsalaro.com>
16Date: Mon Jun 6 00:14:40 2016 +0200
17
18 first
19
20commit 3dabef2ecd20252a90cc819b4634ea16e17500eb
21Author: jdsalaro <noreply@jdsalaro.com>
22Date: Sun Jun 5 23:57:46 2016 +0200
23
24 Added README.md
However, when looking at the history of the main branch on the origin remote, we see that the commit of second is missing. This is so since we haven’t pushed our changes to the remote repository. In other words, we haven’t told the remote repository to incorporate our changes, this is what pushing is all about.
1[~/gitrepo]$ git log origin/main
2commit 9d357c22216ae40cc8babb84b72d11fce03879dc
3Author: jdsalaro <noreply@jdsalaro.com>
4Date: Mon Jun 6 00:18:46 2016 +0200
5
6 remove first
7
8commit e14f7b699680fe4e8093e2b9a6764a2c1ef53ca0
9Author: jdsalaro <noreply@jdsalaro.com>
10Date: Mon Jun 6 00:14:40 2016 +0200
11
12 first
13
14commit 3dabef2ecd20252a90cc819b4634ea16e17500eb
15Author: jdsalaro <noreply@jdsalaro.com>
16Date: Sun Jun 5 23:57:46 2016 +0200
17
18 Added README.md
We now push the changes.
1[~/gitrepo]$ git push -u origin/main
2Counting objects: 2, done.
3Delta compression using up to 4 threads.
4Compressing objects: 100% (2/2), done.
5Writing objects: 100% (2/2), 245 bytes | 0 bytes/s, done.
6Total 2 (delta 0), reused 0 (delta 0)
7To git@server.com:example.git
8 9d357c2..27a6184 main -> main
It can now be observed, that the remote repository has incorporated our changes and these are now shown in the history.
1[~/gitrepo]$ git log origin/main
2commit 27a6184451cd4f383c9b28336a223bc791813384
3Author: jdsalaro <noreply@jdsalaro.com>
4Date: Mon Jun 6 00:20:56 2016 +0200
5
6 second
7
8commit 9d357c22216ae40cc8babb84b72d11fce03879dc
9Author: jdsalaro <noreply@jdsalaro.com>
10Date: Mon Jun 6 00:18:46 2016 +0200
11
12 remove first
13
14commit e14f7b699680fe4e8093e2b9a6764a2c1ef53ca0
15Author: jdsalaro <noreply@jdsalaro.com>
16Date: Mon Jun 6 00:14:40 2016 +0200
17
18 first
19
20commit 3dabef2ecd20252a90cc819b4634ea16e17500eb
21Author: jdsalaro <noreply@jdsalaro.com>
22Date: Sun Jun 5 23:57:46 2016 +0200
23
24 Added README.md
At this point it is said that the changes have successfully been pushed.
It is worth noting that it is not necessary to push every commit. One can, indeed, work on a cloned repository and create several commits. Then, when the time is appropriate, all the changes can be pushed at once.
Pulling#
Pulling refers to the act of obtaining changes present in a remote repository which have not been incorporated in the local copy of said repository.
In the following example a user clones a git repository, waits a while and performs some changes. Before pushing the changes, however, discrepancies between the local and remote histories of the main branch are found. Therefore, the user pulls the changes which were made on top of his version of the remote repository, before committing his own.
1[~/gitrepo/]$ git clone git@server.com:example.git .
2Cloning into '.'...
3remote: Counting objects: 24, done.
4remote: Compressing objects: 100% (17/17), done.
5remote: Total 24 (delta 2), reused 0 (delta 0)
6Receiving objects: 100% (24/24), done.
7Resolving deltas: 100% (2/2), done.
8Checking connectivity... done.
9
10[~/gitrepo/]$ ls -a
11total 20
12drwxrwxr-x 3 user user 4096 Jun 6 18:15 .
13drwxrwxrwt 17 user user 4096 Jun 6 18:15 ..
14drwxrwxr-x 8 user user 4096 Jun 6 18:15 .git
15-rw-rw-r-- 1 user user 11 Jun 6 18:15 myfile
16
17[~/gitrepo/]$ cat myfile
18Hello world
19
20[~/gitrepo/]$ echo 'Goodbye world' >> myfile
Up until this point nothing too interesting has happened. The repository was cloned and myfile changed. This last change hasn’t been committed. or pushed yet, we will first check if there are new changes in the remote repository, to which we would like to push the change.
The last commit on the local history is the following:
1[~/gitrepo/]$ git log -n1
2commit 6d773d7c6b060424754186b173a4ff79815b88ce
3Author: jdsalaro <noreply@jdsalaro.com>
4Date: Mon Jun 6 16:15:01 2016 +git-tutorial
5
6 Greet the world
The last commit in the remote branch, however, seems to be different.
1[~/gitrepo/]$ git fetch
2remote: Counting objects: 3, done.
3remote: Compressing objects: 100% (2/2), done.
4remote: Total 3 (delta 0), reused 0 (delta 0)
5Unpacking objects: 100% (3/3), done.
6From server.com:example
7 6d773d7..d95ecd1 main -> origin/main
8
9[~/gitrepo/]$ git log -n2 origin/main
10commit d95ecd19f7590fd874cfe2b116c20264e4a01477
11Author: jdsalaro <noreply@jdsalaro.com>
12Date: Mon Jun 6 16:17:38 2016 +git-tutorial
13
14 Hello again
15
16commit 6d773d7c6b060424754186b173a4ff79815b88ce
17Author: jdsalaro <noreply@jdsalaro.com>
18Date: Mon Jun 6 16:15:01 2016 +git-tutorial
19
20 Greet the world
There is one commit after 6d773d7c6b060424754186b173a4ff79815b88ce in the remote history, the one with message hello again. We therefore try to pull the changes in that commit but get an error instead.
1[~/gitrepo/]$ git pull
2Updating 6d773d7..d95ecd1
3error: Your local changes to the following files would be overwritten by merge:
4 myfile
5Please, commit your changes or stash them before you can merge.
6Aborting
It turns out, that our working tree is in a dirty state(in this case it has differences with respect to the HEAD). This means that by pulling from the remote repository git would have to clobber(overwrite) changes which haven’t been saved anywhere. This would potentially lead to data loss and hence git aborts the operation.
In order to continue, we put our changes in the stash for later use.
1[~/gitrepo/]$ cat myfile
2Hello world
3Goodbye world
4
5[~/gitrepo/]$ git stash
6Saved working directory and index state WIP on main: 6d773d7 Greet the world
7HEAD is now at 6d773d7 Greet the world
8
9[~/gitrepo/]$ cat myfile
10Hello world
We now pull as was intended initially.
1[~/gitrepo/]$ git pull
2Updating 6d773d7..d95ecd1
3Fast-forward
4myfile | 3 ++-
51 file changed, 1 insertions(+), 0 deletion(-)
6
7[~/gitrepo/]$ cat myfile
8Hello world
9Hello again
10[~/gitrepo/]$
11
12[~/gitrepo/]$git status
13On branch main
14Your branch is up-to-date with 'origin/main'.
15nothing to commit, working directory clean
16[~/gitrepo/]$
At this point the local repository is up-to-date.
Nonetheless, we are forgetting something: there was a change we wanted to apply before realizing that there were changes to pull from the remote main branch. The objective was to append Goodbye world to myfile but instead of doing this we saved this change for later in the stash.
To re-apply the change we have saved in the stash we can use git stash pop. Unfortunately, we get a conflict error message from git.
1[~/gitrepo/]$git stash pop
2Auto-merging myfile
3CONFLICT (content): Merge conflict in myfile
This means that git does not know how to merge the two versions of myfile.
The local one, which is also the one in the head of the main branch, looks like this:
1Hello world
2Hello again
The one saved in the stash, however, looks like this:
1Hello world
2Goodbye world
We are now in the terrain of conflict resolution.
Resolving Conflicts#
Let’s go again over what brought us to having conflicts in our local repository in the first place. Below you’ll find the terminal output shown in the past section, in it we:
clone a repository
check the contents of
myfilemodify
myfilecheck the local commit chain
check the remote commit chain
notice that there are new changes on origin/main and try to pull them
pull fails due to a dirty working tree
remove index and modifications by stashing them
successfully pull changes
try to apply the contents of the stash to the current working tree
git stash popfails, since it is based on the parent of theHEADbut the changes contained in it differ from those inHEAD
1[~/gitrepo/]$git clone git@server.com:example.git .
2
3Cloning into '.'...
4remote: Counting objects: 3, done.
5remote: Total 3 (delta 0), reused 1 (delta 0)
6Receiving objects: 100% (3/3), done.
7Checking connectivity... done.
8
9[~/gitrepo/]$ls -a
10total 16
11drwxrwxr-x 3 user user 4096 Jun 7 22:49 .
12drwxrwxrwt 30 user user 4096 Jun 7 22:49 ..
13drwxrwxr-x 8 user user 4096 Jun 7 22:49 .git
14-rw-rw-r-- 1 user user 12 Jun 7 22:49 myfile
15
16[~/gitrepo/]$cat myfile
17Hello world
18
19[~/gitrepo/]$echo -e "\nGoodbye world" >>myfile
20
21[~/gitrepo/]$git log -n1
22
23commit cd2eb6563b566a2994c4b836e8974e9f71106825
24Author: jdsalaro <noreply@jdsalaro.com>
25Date: Tue Jun 7 22:49:05 2016 +0200
26 Greet the world
27
28[~/gitrepo/]$git fetch
29remote: Counting objects: 3, done.
30remote: Total 3 (delta 0), reused 1 (delta 0)
31Unpacking objects: 100% (3/3), done.
32From server.com:example
33 cd2eb65..6906bf3 main -> origin/main
34
35[~/gitrepo/]$git log -n2 origin/main
36commit 6906bf3594fcb82496e2e5b8da9b3279549d5d09
37Author: jdsalaro <noreply@jdsalaro.com>
38Date: Tue Jun 7 20:52:02 2016 +git-tutorial
39
40 Hello again
41
42commit cd2eb6563b566a2994c4b836e8974e9f71106825
43Author: jdsalaro <noreply@jdsalaro.com>
44Date: Tue Jun 7 22:49:05 2016 +0200
45
46 Greet the world
47
48[~/gitrepo/]$cat myfile
49Hello world
50Goodbye world
51
52[~/gitrepo/]$git pull
53Updating cd2eb65..6906bf3
54error: Your local changes to the following files would be overwritten by merge:
55 myfile
56Please, commit your changes or stash them before you can merge.
57Aborting
58
59[~/gitrepo/]$cat myfile
60Hello world
61Goodbye world
62
63[~/gitrepo/]$git stash
64Saved working directory and index state WIP on main: cd2eb65 Greet the world
65HEAD is now at cd2eb65 Greet the world
66
67[~/gitrepo/]$git pull
68Updating cd2eb65..6906bf3
69Fast-forward
70myfile | 1 +
711 file changed, 1 insertion(+)
72[~/gitrepo/]$git status
73On branch main
74Your branch is up-to-date with 'origin/main'.
75nothing to commit, working directory clean
76
77[~/gitrepo/]$git stash pop
78Auto-merging myfile
79CONFLICT (content): Merge conflict in myfile
Conflict resolution is a topic which seems mysterious at first but once understood turns out to be quite straight forward. It refers to the act of manually merging changes when git has not been able to merge them automatically. This usually involves manually editing the files involved and adding them to the stage.
git stash pop tries to apply the commit on top of the stash to the current working directory, so in a sense, it also works as git merge, only that it merges a commit and not a branch.
Calling git merge leads to an error similar to the one we’ve already seen. There are changes which have not been yet merged and they have to be solved in order to proceed.
1[~/gitrepo/]$git merge
2error: merge is not possible because you have unmerged files.
3hint: Fix them up in the work tree, and then use 'git add/rm <file>'
4hint: as appropriate to mark resolution and make a commit.
5fatal: Exiting because of an unresolved conflict.
We observe that git has modified the file with conflicting changes.
myfile now contains the change add "Hello again" on the second line which comes from origin/main and our local change which we popped from the stash `add “Goodbye world” at the second line.
1[~/gitrepo/]$ls -a
2total 20
3drwxrwxr-x 3 user user 4096 Jun 7 22:57 .
4drwxrwxrwt 30 user user 4096 Jun 7 22:56 ..
5drwxrwxr-x 8 user user 4096 Jun 7 22:57 .git
6-rw-rw-r-- 1 user user 96 Jun 7 22:57 myfile
7
8[~/gitrepo/]$cat myfile
9Hello world
10<<<<<<< Updated upstream
11Hello again
12=======
13Goodbye world
14>
We open myfile with a text editor and modify it in the way which best suits us.
1[~/gitrepo/]$cat myfile
2Hello world
3Hello again
4Goodbye world
We have kept both changes. Now we add the file again to the index. This is our way of telling git that the conflicts for myfile have been solved.
1[~/gitrepo/]$git add myfile
2
3[~/gitrepo/]$git status
4On branch main
5Your branch is up-to-date with 'origin/main'.
6Changes to be committed:
7 (use "git reset HEAD <file>..." to unstage)
8
9 modified: myfile
myfile is now listed as modified but not committed. So we commit it and push it.
1[~/gitrepo/]$git commit -m "Fixed conflict"
2
3[main e1bc4c8] Fixed conflict
41 file changed, 1 insertion(+)
5
6[~/gitrepo/]$git push
7Counting objects: 3, done.
8Writing objects: 100% (3/3), 266 bytes | 0 bytes/s, done.
9Total 3 (delta 0), reused 0 (delta 0)
10To git@server.com:example.git
11 6906bf3..e1bc4c8 main -> main
origin/main now contains our changes.
1[~/gitrepo/]$git log -n3 origin/main
2commit e1bc4c8c51387858f1533521510a27e51e65dd58
3Author: jdsalaro <noreply@jdsalaro.com>
4Date: Tue Jun 7 23:01:08 2016 +0200
5
6 Fixed conflict
7
8commit 6906bf3594fcb82496e2e5b8da9b3279549d5d09
9Author: jdsalaro <noreply@jdsalaro.com>
10Date: Tue Jun 7 20:52:02 2016 +git-tutorial
11
12 Hello again
13
14commit cd2eb6563b566a2994c4b836e8974e9f71106825
15Author: jdsalaro <noreply@jdsalaro.com>
16Date: Tue Jun 7 22:49:05 2016 +0200
17
18 Greet the world
19[~/gitrepo/]$
As you’ve might have noticed, manually solving merging conflicts is a troublesome task. It involves moving text around, copying, deleting and so on. It is for this reason that local GUIs for merging and solving conflicts or services such as GitLab, GitHub and BitBucket might be a better alternative. My favorite local tool is Meld and as project management service I use GitLab.
We can set meld as our default merge.tool by installing it and issuing git config --global merge.tool meld. Under Ubuntu it can be easily installed with sudo apt-get install meld.
1[~/gitrepo/]$git mergetool
2Merging:
3myfile
4
5Normal merge conflict for 'myfile':
6 {local}: modified file
7 {remote}: modified file
At this point git calls our chosen tool.
As you can see, the text in origin/main is shown on the left, while our changes are shown on the right. The final contents of myfile are shown in the middle.
A good thing about Meld is that it generates a myfile.orig file, which contains the file before the conflict resolution, just in case something went wrong.
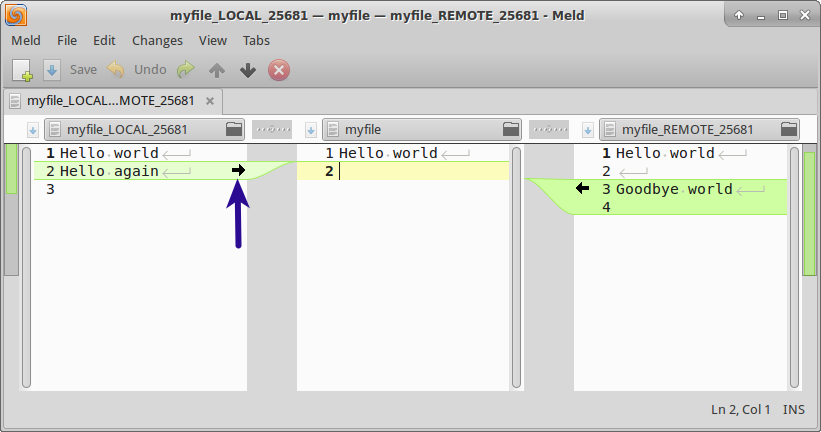
Initial conflict view in Meld#
In this case we choose to only keep the remote changes and discard our own by clicking on the arrow to the left. Finally, we save the changes and close the GUI by using CTRL+S and then CTRL+Q.
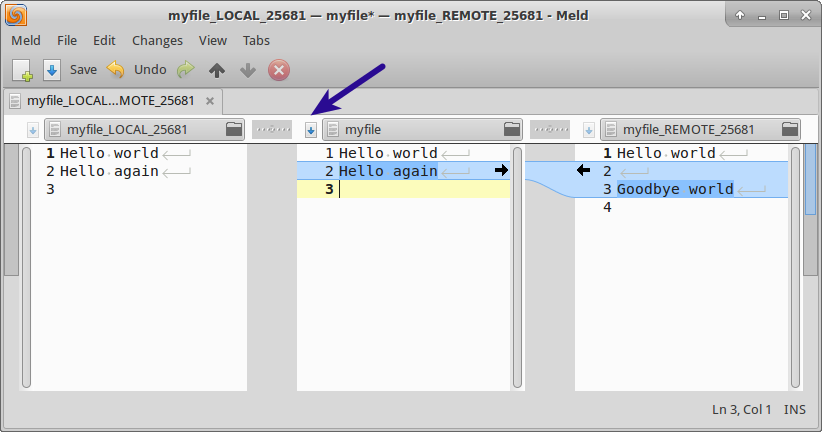
Incorporating changes with Meld#
If we try to run our mergetool again, git lets us know that there are no more changes to be solved.
1[~/gitrepo/]$git mergetool
2No files need merging
3
4[~/gitrepo/]$git status
5On branch main
6Your branch is up-to-date with 'origin/main'.
7Untracked files:
8 (use "git add <file>..." to include in what will be committed)
9
10 myfile.orig
11
12nothing added to commit but untracked files present (use "git add" to track)
13
14[~/gitrepo/]$cat myfile.orig
15Hello world
16<<<<<<< Updated upstream
17Hello again
18=======
19Goodbye world
20>>>>>>> Stashed changes
myfile.orig is still there and can be removed. Another alternative would be to put files with a .orig extension in .gitignore if you wish to keep such files locally.
In any case, myfile looks as follows.
1[~/gitrepo/]$cat myfile
2Hello world
3Hello again
In this way we have managed to solve merging conflicts caused by edit collisions.
Advanced topics#
Dangling commits#
Dangling commits are commits which aren’t associated with any branch. They exist in the history but are not tied to any line of development, they exist as “islands” in the commit history without parents or children in the chain. They are what makes the git stash possible.
The Stash#
Stashing changes is a quick and easy way to generate a commit containing all changes which haven’t been added to the index and store them away as to not lose them. As explained by the git manpage, the command git stash “stash(es) the changes in a dirty working directory away”. Furthermore, “use git stash when you want to record the current state of the working directory and the index, but want to go back to a clean working directory.”
The stash works as a stack on top of which one can put dangling commits until one desires to use them or apply them to another commit. Sort of putting together everything you haven’t quite had the time to properly organize and commit it to some place for later use.
1[~/gitrepo]$ ls
2total 12
3drwxrwxr-x 3 user user 4096 Jun 5 22:47 .
4drwxrwxrwt 14 user user 4096 Jun 5 22:47 ..
5-rw-rw-r-- 1 user user 0 Jun 5 22:47 file
6drwxrwxr-x 8 user user 4096 Jun 5 22:47 .git
7-rw-rw-r-- 1 user user 0 Jun 5 22:46 README.md
8
9[~/gitrepo]$ git status --short
10?? file
As seen from the previous output, file is untracked. By using the stash, we can store away all changes to the working directory, including untracked files, which make our working directory dirty using git stash -u and retrieve them later on.
1[~/gitrepo]$ git stash -u
2Saved working directory and index state WIP on main: 4963f48 Initial commit
3HEAD is now at 4963f48 Initial commit
Consequently, file has “disappeared” and our working tree is once again reflecting the head of the main branch.
1[~/gitrepo]$ ls
2total 12
3drwxrwxr-x 3 user user 4096 Jun 5 22:47 .
4drwxrwxrwt 14 user user 4096 Jun 5 22:47 ..
5drwxrwxr-x 8 user user 4096 Jun 5 22:47 .git
6-rw-rw-r-- 1 user user 0 Jun 5 22:46 README.md
7
8[~/gitrepo]$ git status
9On branch main
10nothing to commit, working directory clean
Nonetheless, there is one entry, snapshot, in the stash which contains our former working tree and index.
1~/gitrepo]$ git stash list
2stash@{0}: WIP on main: 4963f48 Initial commit
By popping the first entry on the stash we apply the saved changes and restore our former index.
[~/gitrepo]$ git stash pop
Already up-to-date!
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
file
nothing added to commit but untracked files present (use "git add" to track)
Dropped refs/stash@{0} (47f58adf2bf6e448964314619403649b79bfc8d1)
This leads to file appearing once again in our working tree.
[~/gitrepo]$ ls -a
total 12
drwxrwxr-x 3 user user 4096 Jun 5 22:51 .
drwxrwxrwt 14 user user 4096 Jun 5 22:47 ..
-rw-rw-r-- 1 user user 0 Jun 5 22:51 file
drwxrwxr-x 8 user user 4096 Jun 5 22:51 .git
-rw-rw-r-- 1 user user 0 Jun 5 22:46 README.md
file is also once again listed, as it should be, as untracked.
1[~/gitrepo]$ git status
2On branch main
3Untracked files:
4 (use "git add <file>..." to include in what will be committed)
5
6 file
7
8nothing added to commit but untracked files present (use "git add" to track)
There are some topics I’ve purposely left out since I consider them to be out of scope. I do hope, however, that with what I’ve presented so far you will now be better equipped to delve into those topics on your own. For completeness’ sake, the topics I left out but you might want to look into after you’ve gained more confidence with git:
resetting
cherry-picking
rebasing
git workflows
Finally, I’ve prepared a cheatsheet with my favorite commands which I hope you find useful; you can find it here.
Final words#
As far as basic git terminology and usage goes, that was pretty much it. In case you’re wondering how you’ll remember all of this, I’ve prepared a git cheatsheet you can use as reference going forward. Some you’ll use on a daily basis, some others once every month, but it’s good to have a source you can use every once in a while to get a refresher and remember what’s out there. I’ve also decided to include some more advanced one-liners in order to give you an idea of what’s possible with git.
One more thing, practice what you’ve read so far! Create a local repository or head over to Gitlab, GitHub or BitBucket and create a project and git repository. Practice cloning, adding files, committing changes, creating branches, merging and so on. With enough practice you’ll become familiar enough with git to start fine-tuning your usage of the tool and your workflow.
Stay in touch by entering your email below and receive updates whenever I post something new:
As always, thank you for reading and remember that feedback is welcome and appreciated; you may contact me via email or social media. Let me know if there's anything else you'd like to know, something you'd like to have corrected, translated, added or clarified further.
Further Reading#
GitLab’s tutorials under https://docs.gitlab.com/ee/tutorials are a good read as well as the official git-scm book which can be found under https://git-scm.com/book/en/v2/